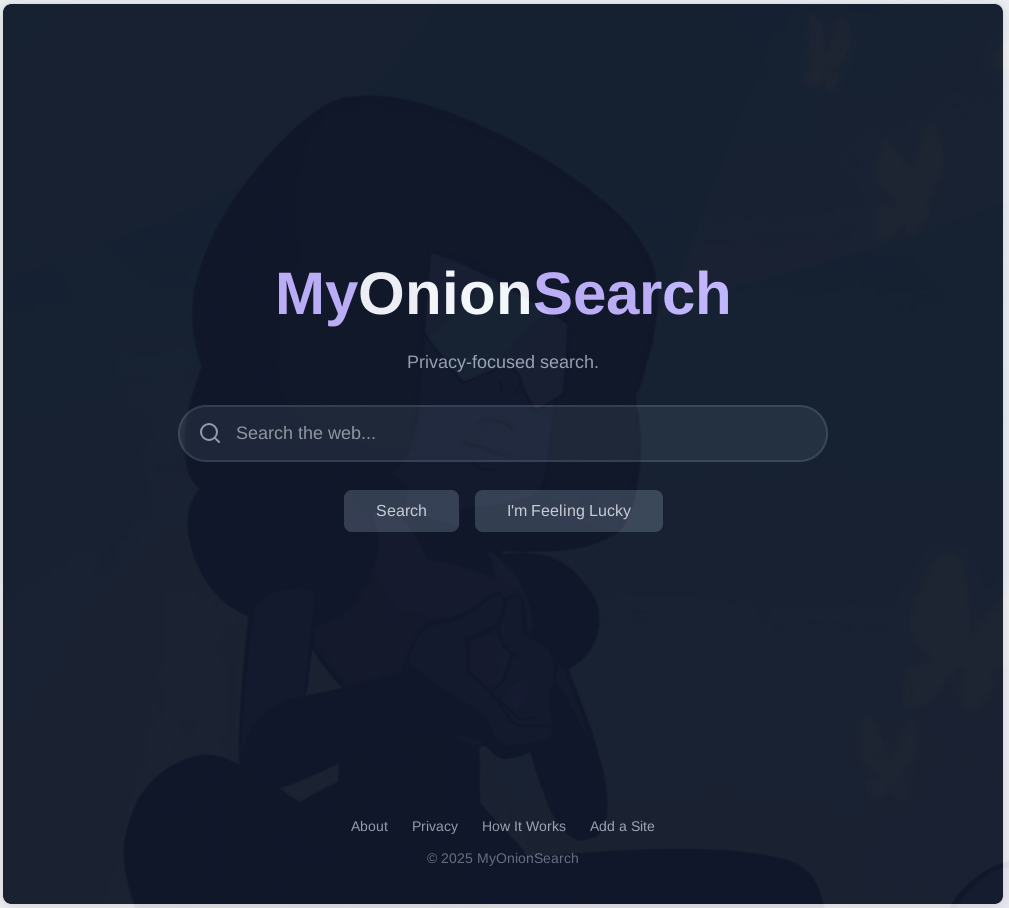
Project: MyOnionSearch
A privacy-first, community-driven search engine for the Tor network.
- Project Overview
MyOnionSearch is a search engine I built from the ground up to provide a safe, simple, and privacy-respecting way to find content on the Tor network. The project's core principle is zero-logging; it never logs user IP addresses, search queries, or browsing habits.
The system is composed of two main Go applications: the public-facing web server and a distributed, scalable backend crawler.
- A Pivot to Simplicity: From Flutter to HTML
I initially prototyped the frontend using Flutter, aiming for a modern, app-like feel. However, I quickly realized this approach was fundamentally at odds with the goals of a privacy-focused service, especially one operating on the high-latency Tor network.
Performance: The large JavaScript bundles required by modern frameworks are impractical for the low-bandwidth nature of Tor.
Privacy & Security: A "No-JS" (No-JavaScript) approach is the gold standard for privacy. It completely eliminates the risk of client-side tracking and ensures the site is 100% functional for users who (rightfully) disable scripts.
I pivoted to a lightweight, server-rendered frontend using plain HTML and CSS. This decision resulted in a site that is blazing-fast, accessible to all, and has a minimal security footprint.
- The Go Backend & Frontend
The backend is a lightweight, standard Go web server that serves two roles:
Static Server: It serves all the static assets (HTML, CSS), making the application self-contained.
API & Templating: It provides a JSON API for searching and adding sites. For the "No-JS" frontend, it uses Go's built-in html/template package to render the search results page on the server before sending it to the user.
- The Distributed Go Crawler
To build and maintain the search index, I designed a scalable, distributed crawling system built around a producer-consumer architecture using Redis as a job queue. This decouples scheduling work from executing work, which is essential for the unreliable Tor network.
The Producer: A single, long-running Go process that acts as the "scheduler." It queries the database for work (e.g., "find 100 sites not checked in 6 hours") and adds health_check or recursive_crawl jobs to the Redis queue.
The Workers: A fleet of stateless Go programs. I can run one worker or thousands in parallel, even on different servers. Each worker pulls a single job from Redis, connects to the Tor network via a SOCKS5 proxy to perform its task, updates the database, and then goes back to the queue for another job.
This design makes the crawler horizontally scalable, resilient to failures, and ensures that the core web server's performance is never affected by slow crawl operations.